




🎤 이 아티클은 4회차 구름 세미나에서 레몬트리 CTO 강대명 님이 강의해주신 내용을 바탕으로 재구성되었습니다.
우리 서비스는 장애에 강하고
확장 가능할까요?
저는 백엔드 엔지니어입니다. 인프라 엔지니어가 아닌 백엔드 관점에서 시스템 아키텍처와 인프라 구성에 관해 이야기 드리려고 해요. 이번 발표에서는 MSA(Micro Service Architecture)나 특정 아키텍처를 다루지는 않습니다.
인프라 구성에 정답은 없습니다
기업 규모에 따라 다르기 때문인데요. 스타트업에 좋은 인프라가 대규모 서비스에도 좋은 건 아닙니다. 보통 많은 분이 이야기하시는 좋은 인프라는 뭘까요?
1. 장애에 강건하고
2. 확장이 쉽고
3. 관측이 쉽고
4. 비용이 적게 듭니다.
1~3번과 4번은 모순적이죠. 장애에 강하고 확장과 관측이 쉬우려면 돈이 많이 들 수밖에 없습니다. 대규모 서비스로 갈수록 좋은 인프라가 필요하고 그러려면 비용이 많이 필요해요.
스타트업이라면
처음 서비스를 만드신다면 클라우드로 할 건지, 온프레미스(On-Premise) 서버로 직접 구축할 건지 고민하실 텐데요, 무조건 클라우드를 추천합니다. 법적으로 클라우드를 사용하지 못하는 금융, 의료 등 일부 분야를 제외하면 답은 클라우드인데요. 단순히 클라우드가 좋고 IDC(Internet Data Center)가 나빠서는 아닙니다.
온프레미스를 할 수 있는 회사는 2가지라고 생각해요. 첫 번째는 여유 장비가 충분히 있어서 새로운 장비의 수급이 급하지 않은 회사, 두 번째는 좋은 SE(System Engineer)를 채용하고 있는 회사인데요.
요즘은 온프레미스를 하려고 해도 장비 수급이 어렵습니다. 반도체 대란이죠. 저희 회사가 작년 11월에 네트워크 장비를 시켰는데 배송 날짜가 내년 2월이에요. 온프레미스를 하려면 라우터, 스위치, 서버를 모두 필요한데 언제 도착할지 알 수 없다면 시작도 못 하는 거죠. 하드웨어를 여유롭게 보유하고 있는 회사가 아니라면 온프레미스는 힘들 거예요.
물리적인 인프라를 구성하고, 네트워크 스위치를 다룰 줄 아는 시스템 엔지니어를 찾기도 어렵습니다. 대부분의 장애는 새벽에 많이 발생하는데 온프레미스라면 IDC에 뛰어가야 할 때도 있거든요. 특히 스타트업에서는 할 수 없는 거죠.
스타트업에서는 MVP 출시가 우선입니다. 간단한 서비스 아키텍처를 그리면 이런 모습이에요.

여기서 스위치와 라우터를 포함한 모든 걸 이중화하는 게 중요합니다. 기본적으로 LB(Load Balancer)는 2개, API 서버들은 LB 뒤에 붙어 있습니다. 가장 중요한 DB 데이터는 DBMS에 있죠. 데이터는 Primary, Replica를 둬서 레플리케이션(Replication)을 받아 구성합니다. 레플리케이션은 여러 개의 DB를 권한에 따라 수직적인 구조로 구축하는 방식이에요. 위 아키텍처라면 서비스 초창기에 장애가 발생해도 어느 정도 버틸 수 있습니다.
AWS로 보면 아래와 같아요. 빈스토크(Beanstalk)말고 AWS를 쓰신다면 EKS나 ECS를 사용하실 수도 있어요. EKS는 충분히 잘 아는 사람이 없으면 도리어 관리가 더 힘들 수 있습니다.

서비스 인프라는 모니터링이 굉장히 중요합니다. AWS면 프로메테우스(Prometheus)나 그라파나(Grafana), 텔레그래프(Telegraph) 등으로 직접 모니터링 할 수도 있고, AWS 클라우드워치(CloudWatch)가 데이터를 넘겨주기도 합니다. 데이터독(Datadog)이나 뉴렐릭(New Relic), 센트리(Sentry)를 사용할 수도 있고요.
저희는 클라우드워치로 에러를 보내고 로그 인사이트로 시간당 에러 수가 많은 순서대로 카운트합니다. 당연히 장애가 발생하면 상위 1~2개 정도가 에러 원인과 관련 있겠죠?
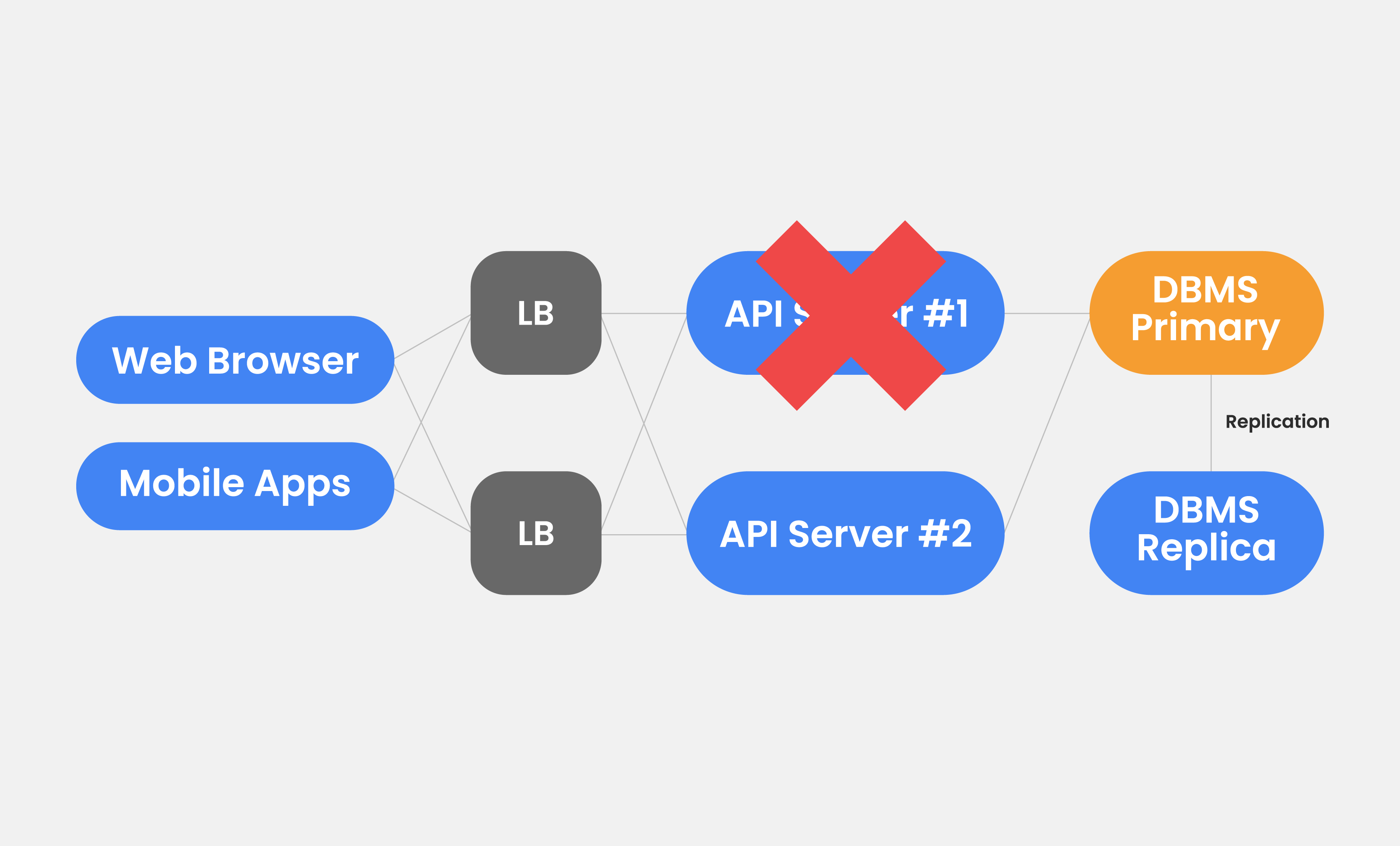
용량(Capacity) 문제도 고려해야 합니다. 만약 API 서버가 2대인데 1대가 죽었다고 생각해 볼까요? 위 구조라면 1대가 죽어도 아래 서버로 서비스는 유지되겠죠. 일부 장애에도 서비스는 작동해야 합니다. High Availability 줄여서 HA라고 하는데요.
만약 API 서버가 한 번에 100개의 Request만 처리할 수 있다고 가정해 봅시다. 200개의 Request를 처리하려면 2대, 300개를 처리하려면 3대가 필요하죠. 하지만 실제로는 다릅니다. 로드 밸런서가 200개를 정확히 100개-100개로 나눠주지 않기 때문이에요. 항상 대수를 넉넉하게 잡으셔야 합니다.
클라우드나 쿠버네티스를 사용하면 서버를 늘리기 쉽지만, 온프레미스라면 장비 증설을 미리 계획해야 해요. 온프레미스에서는 장비를 넣고 빼는 게 불가능하기 때문에 몇 대가 죽어도 남은 장비로 버틸 수 있어야 합니다. 피크 타임을 버틸 수 있는 기준에 딱 맞춰두었다가 서버가 1대라도 죽으면 전체 서비스 성능이 갑자기 떨어질 수 있어요. 사용량 모니터링도 필수입니다.
데이터 복제(Data Replication)도
중요합니다

만약 DBMS에 장애가 났는데 데이터 복제(Data Replication)를 해두지 않았다면 데이터가 몽땅 사라지겠죠. Primary(서비스 하는 DB) 내용을 자동으로 Replica(백업용 DB)에 복제해주는 작업이 필요합니다. 2대의 서버에 같은 내용이 저장되어 있다면 1대에 문제가 생겨도 다른 서버로 서비스할 수 있죠.
Primary에 문제가 생겨 Replica로 바뀌는 걸 페일오버(failover)라고 하는데요, API 서버에 장애가 발생하면 새로운 서버를 띄워 추가하는 개념이라면, DBMS나 캐시 서버는 다른 친구가 처리할 수 있도록 바꿔준다는 차이가 있어요.
이 과정을 쉽게 도와주는 IaC(Infrastructure as Code)는 대표적으로 테라폼(Terraform)이 있습니다. 이런 툴을 사용해 인프라 변경 내역을 관리하면 좋아요. 변경 내역을 관리하면 복원이 쉬워집니다. 변경 히스토리가 남기 때문에 누구든 원래대로 복구할 수 있어요.
기존에 IaC를 안 쓰고 계셨다면 처음 적용하는 게 쉽지는 않습니다. 인프라를 부분적으로 바꿔야 하기 때문에 달리는 기차에서 바퀴를 바꾸는 것과 비슷한데요. 조금씩 시간을 들여 전환하는 걸 추천합니다.
대규모 서비스라면
대규모 서비스는 크게 트래픽 범위를 예측할 수 있는 경우와 없는 경우로 나눌 수 있습니다. 보통 네이버나 카카오 같은 서비스는 트래픽 예측이 가능할 거예요. 새해 이벤트, 블랙 프라이데이, 사이버 먼데이, 광군절 등 큰 이벤트에 영향을 받는 곳도 예상할 수 있겠죠.
트래픽 범위를 예측할 수 없는 경우에는 보통 오토스케일링(Auto-Scaling)으로 커버하는데요, 사실 오토스케일링도 분 단위 대응은 어렵습니다. 분 단위로 몇 백 만 명이 들어오면 오토스케일링으로 해결이 안 됩니다. 미리 서버를 늘려 두는 수밖에 없어요. 다만 기술이 많이 발전해서 어느 정도의 트래픽은 돈으로 해결할 수 있습니다.

대규모 서비스라고 구조가 다른 건 아닙니다. 매우 많은 API 서버와 매우 좋은 DB 서버가 있을 뿐이죠. DB가 1대라도 동시 접속 몇 백 만까지 버틸 수 있는 든든한 친구들이에요.
대부분의 서비스는 Read가 80% 정도 됩니다. Write가 아무리 많다고 하더라도 50%를 넘어가지 못해요. 좋은 캐시 서버와 DB 서버 조합을 사용하면 많은 트래픽을 소화할 수 있습니다.
대규모 서비스는 모든 상황에 대비해야 하지만, 대부분 데이터 이슈를 걱정하실 텐데요, 사실 API 서버가 부족해 장애가 발생하는 경우에 API 서버를 추가하는 건 어렵지 않습니다. 요새는 클라우드를 띄우면 ELB에 자동으로 붙기도 해 ELB 주소만 가지고 있으면 서버 대수를 몰라도 괜찮더라고요.
좋은(비싼) DBMS와 캐시를 써도 데이터에 문제가 생기는 경우가 있습니다. Cloud Spanner, Azure Cosmos DB, Amazon DynamoDB, vitess, Cockroach DB 등은 ‘샤딩(Sharding, Shared Nothing)’을 제공하고 있어요.
데이터를 분리해야 합니다


샤딩을 이야기하기 전에 DB 파티셔닝(Partitioning)을 먼저 이야기하려고 해요. DB 파티셔닝에는 Vertical Partitioning과 Horizontal Partitioning이 있습니다. Vertical Partitioning은 테이블을 컬럼(Column) 단위로 쪼개는 거예요. 많이 쓰는 컬럼만 따로 모아 테이블로 만들면 접근 속도가 빠르거든요. Horizontal Partitioning은 테이블의 스키마(Schema)는 동일한데 특정 키를 기준으로 분리합니다.
대규모 서비스에서는 Vertical과 Horizontal 중 어떤 구조를 선택하는 게 좋을까요? 정답은 둘 다입니다. 둘 다 써야 하지만 샤딩은 보통 Horizontal Partitioning을 말해요.
샤딩(Sharding)

샤딩은 데이터를 여러 조각으로 나눠 저장하는 기술이에요. 특정 데이터와 키를 편하게 찾으려고 사용하죠. 결국 찾으려고 저장하는 거니까요. 만약 데이터를 DB #1, #2, #3중 랜덤으로 저장하면 모든 DB를 다 찾아봐야 해요. 그러면 모든 DB에 부하가 가게 됩니다. 특정 룰을 정해 쉽게 찾을 수 있으면 바로 해당 서버에 가면 되니 부하가 줄어들겠죠.
대규모 서비스의 핵심은 데이터입니다. 데이터를 나누는 방법으로 가장 많이 쓰는 게 샤딩이에요. 샤딩에도 여러 가지 방법이 있는데 가장 간단하고 많이 사용하는 ‘레인지 샤딩(Range Sharding)’을 소개해 드릴게요. 보통 스타트업에서는 샤딩을 고려하지 않지만, 샤딩을 생각할 정도로 서비스가 커지면 가장 먼저 고려하는 방법이기도 해요.
레인지 샤딩(Range Sharding)

레인지 샤딩은 특정 대역으로 데이터를 나누는 방식입니다. User 1~100까지는 1번 서버, 101~200까지는 2번 서버로 나누죠. 만약 User 101~200이 빠진다면 2번 서버는 텅 비게 되겠죠? 서비스 부하에 불균형이 생긴다는 단점이 있어요. 특정 서버의 로드가 낮다면 신규 유저를 해당 서버에 저장하는 방식으로 해결해야 합니다. Range 관리가 중요해요.
샤딩도 단점이 있습니다. RDBMS에 자체적으로 샤딩을 구현하면 Join 연산을 할 수 없어요. 보통 서비스를 만들 때 생각 외로 Join을 많이 씁니다. 데이터가 일부는 A 서버, 일부는 B 서버, 일부는 C 서버에 있는데 Join 해버리면 결국 다 찾아서 다시 합쳐야 한다는 이야기거든요.
인프라를 구축할 때
미리 고민하면 좋은 것
스타트업은 일단 제품이 나오는 게 중요해서 어느 정도 성공하면 돈과 인력을 써 서비스 구조를 개선합니다. 그럼에도 데이터 샤딩 규칙과 인프라 네이밍은 미리 고민하면 좋아요.
데이터 샤딩 규칙을 생각해 놓으면 서비스 확장 시 편합니다. 레인지 샤딩이나 다른 샤딩 방법을 쓸 수 있는 코드 구조를 만들어 두시면 시간은 들지만 분명 도움이 될 거예요.
인프라 네이밍도 중요합니다. AWS 같은 경우 서울, 미국, 일본 리전이 있을 수 있죠. {name} – {region} 등 구분 정보가 필요합니다. 서버 이름만 보고도 어떤 일을 하는 서버인지 알 수 있도록 정리해야 해요. 미리 잘 정리해두면 나중에 인프라를 확장할 때 충돌이 적습니다.
초반에는 인프라 네이밍이 샤딩 규칙보다 더 중요해요. 네이밍 규칙을 잘 정해두지 않으면 서비스 규모가 커졌을 때 큰 문제가 생길 수 있어요. 예전에 이런 경우가 있었어요. 서버 이름이 tiger1, tiger2, tiger3인데 옆 팀에서 tigver13 서버를 내리려다 tiger1, tiger3 서버를 내려버린 거예요. 이런 경우가 실제로 생길 수 있습니다.
온프레미스에서
클라우드로 간다면
온프레미스에서 클라우드로 데이터 처리 엔진을 옮길 때 몇 가지 고민했던 포인트가 있습니다.
가상화 장비들은 같은 사양이라고 같은 성능을 내지 않습니다. 같은 사양을 쓸 수 없는 경우도 있고요. Redis 같은 경우는 CPU 속도에 따라 처리량이 달라지는데 클라우드로 이전하면서 CPU 속도가 늦어져 처리량이 떨어지는 경우도 생깁니다. 이런 것들을 체크하셔야 해요.
같은 소프트웨어가 아닐 수도 있습니다. AWS에서는 이전에 쓰던 쿼리가 안 돌아갈 수도 있어요. 마이그레이션(Migration)을 하실 때 리프트 앤 시프트(Lift and Shift) 방식으로 그대로 구성해본 다음 클라우드 특성에 맞춰서 바꿔야 합니다.
온프레미스에서 클라우드로 이전하면 사고방식의 전환도 필요해요. 보통 온프레미스에서는 이 장비는 절대 고장 나면 안 된다고 생각해요. 장비를 1 대 1로 매칭해서 바꿔야 하거든요. 반면 클라우드에서는 언제든 장비가 생기거나 줄어들 수 있죠. 이런 마인드로 접근하면 서비스 디스커버리 측면에서 변화가 생겨요. 필요하면 만들고 필요 없어지면 지우는 게 유연해집니다.
지금 우리 회사에 맞는
인프라가 좋은 인프라입니다
예전에 제가 참여했던 A 서비스는 DAU가 800만, MAU가 1,500만 정도 됐어요. Daily API Call 수가 4억 2천만 건 정도 됐었죠. 캐시 사용은 Redis가 274대로 5.2 TB, Memcached는 137대로 3.3 TB, 총 8.5 TB 정도를 캐시로만 썼어요. 하루에 수십 번 배포가 가능했었고요.
여러분이나 제가 운영하는 서비스는 이 정도의 규모일까요? 핵심은 우리가 이런 인프라를 구축해야 하느냐는 거예요. 물론 많은 사람이 쓰는 서비스를 운영하고 계시다면 이렇게 구축해야 하겠죠. 하지만 대부분의 스타트업이 고민해야 할 부분은 다릅니다. 이렇게 만들 필요가 없거든요. 좋은 인프라는 거대한 인프라가 아니라 우리 회사의 지금 시점에 맞는 인프라입니다.
Edit Sunny Design Lily










